
Do You Really Need a Message Queue? Handling Background Jobs with Tokio
How far can you get before calling in SQS, RabbitMQ or Kafka?

tl;dr You can get pretty far just using tokio::spawn.
“Notado is a content-first bookmarking service, where the paragraphs and sentences that make you want to bookmark something are treated as first-class citizens rather than pieces of additional metadata.”
Sounds pretty simple, right?
For the most part it is! Usually a user will send Notado either a permalink to a comment, or a highlight from an article along with a URL. Notado will do its thing, and a new entry will be added to the user’s library of saved content.
However, when a user has external integrations configured (other services that saved content should be forwarded to), or when a user begins an import of saved comments from another website (Liked Tweets from Twitter, for example), or an import of Kindle highlights, some additional complexity is introduced that must be addressed (or ignored) in one way or another.
The Earliest Days
In the earliest days of Notado (back when my wife and I were the only users), this complexity was largely ignored. For example, when a user with all available external integrations configured saved a new comment, Notado would wait to send the content to each of them, and would not respond to the user’s HTTP request until all of those calls to the external services had succeeded. And if one of them didn’t succeed? Well…
Similarly, when triggering potentially large imports from Twitter or Reddit, the page would hang while the imports chugged along in real-time and Notado would not respond to the user’s HTTP request until the import had either been completed (or failed). I think we can agree that this sort of behaviour is… less than graceful.
The Conventional Wisdom
In situations like these where a HTTP request from a user triggers a potentially long-running task, many of us will have been conditioned in our working lives to reach for Amazon SQS, RabbitMQ, Kafka or something similar.
If you are someone who has heard of these services and products but hasn’t used them, they basically all provide mechanisms that you can use to store information about a task to be processed later.
“Later” can even just mean something as simple as “not in a HTTP request handler.”
Other processes then periodically check wherever that task information is stored, and if there is anything there, they’ll do whatever they are programmed to do with it.
One of the outcomes of this is that a service is able to respond much quicker to user HTTP requests, and therefore provide a better user experience, because storing some information about a task is almost always going to be faster than executing that task and waiting for its completion before responding to the user.
A Different Approach
I already knew deep down that the conventional wisdom was going to be overkill for Notado’s use case. (I also didn’t want the hassle of deploying and managing even more moving parts…)
I started looking at projects that built on top of PostgreSQL to provide a lightweight messaging queue and even went down the rabbit hole of building one out myself (it was not very good).
Thankfully, it wasn’t long before I came across this comment on the Rocket repository.

I don’t think I can overstate just how much this comment opened my eyes. Suddenly, I realised that I didn’t need anything other than the async runtime that I was already using.
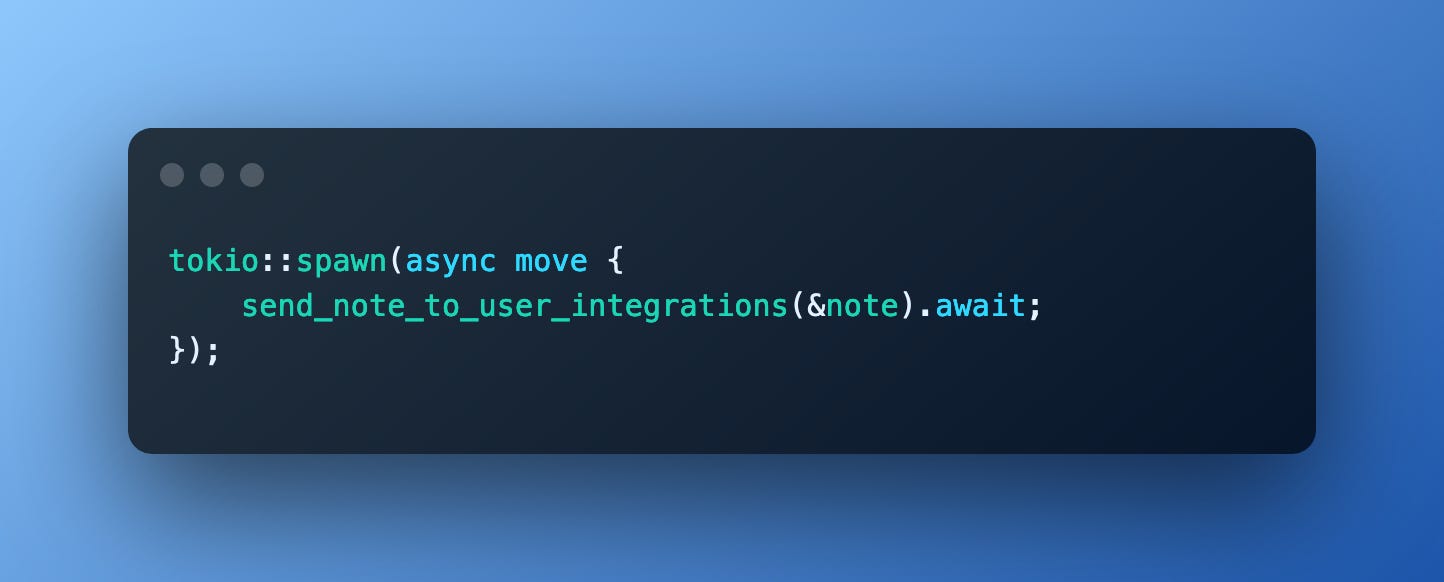
With this change, (small in terms of code, but big in terms of shifting my mental model), Notado would be able to significantly improve the user experience by reducing the time taken to respond to user requests which could trigger potentially long-running tasks.
A Little More Refinement
This is already a huge improvement, but how could we refine this even more? Well, we might want to keep track of any background job failures so that they can either be reported to the user or silently retried after a given period of time.
We might also want to make sure that we handle more extreme cases where one of these jobs is killed before reaching completion by a kill signal from a scheduler or a new version of our service being deployed.
There are any number of ways to go about this, but here is one suggestion to get you started if you decide to go down this route:
When a background job is started in a task spawned with tokio, we can write an entry to a database table, and then when the job is completed successfully, we can delete that entry. The only rows that will be left in that table over a certain age will be for tasks that did not complete successfully, and you can decide what to do with them from there.
Keeping Things Simple
Throughout my years developing, deploying and maintaining software in my professional life, I have come to realise that for me personally, “keeping things simple” is often one of the most difficult things to do.
My mental model has been so warped by working at scale that my default instinct is always to reach for what I know, and what I know is usually completely overkill for my modest needs as a solo developer.
It’s easy to fall into the trap of doing a little with a lot, so I hope that these technical posts can inspire people in a similar position to find ways to do a lot with a little.
Thanks for sticking around until the end! If you want to get in touch, my Twitter handle is @notado_app and you can also find me in the Notado Discord server.
If you would like to reach out by email or request a technical article on a different part of Notado’s technology stack, you can reach me at hello at notado dot app.
If you are interested in what I read in order to come up with solutions like this, you can check out my Software Development feed on Notado, which you can also subscribe to via RSS.
Alternatively, if you’ve had enough technical reading for today, I also use Notado to curate feeds on Addiction (RSS), Capitalism (RSS), and Mental Health (RSS).
Want to try curating and publishing your own feed? Notado is running a free open beta until the end of 2022!